引言
在家里自己用OpenR1准备从qwen-base训出个R1模型来,结果跑了demo数据,发现前100多步的loss几乎都是0:
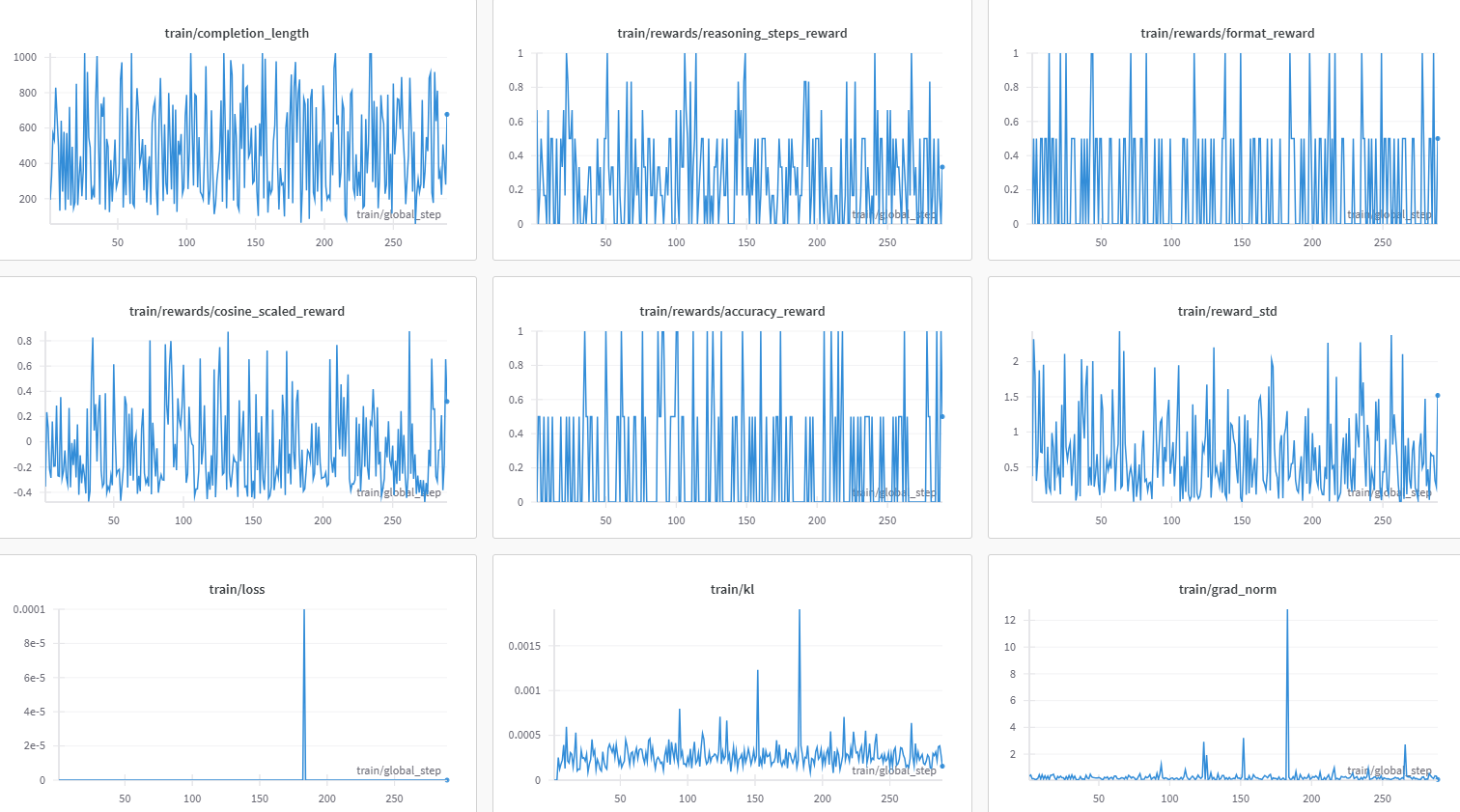
在搜索相关资料时,发现Hugging Face的TRL库中也有类似的问题讨论:
GRPO: 为什么损失在前K步为零,然后随着时间的推移增加?
这表明,GRPO训练初期损失为零可能是一个固有现象。
至于我的loss为啥一直是0,这应该与我的lr等超参有关,这里就不讨论了。
不过,loss从0开始还是引起了我的好奇,让我们来探讨一下。
GRPO Loss函数分析
GRPO(Group Relative Policy Optimization)损失函数:

GRPO Trainer
可以发现,grpo的loss可近似看作:
[ \text{Loss} \approx \frac{\pi_\theta}{\pi_\theta} \cdot A - \beta \cdot \text{KL} ]
其中,(\pi_\theta)表示当前策略,(A)表示奖励函数,(\beta)是KL散度的权重。
这里πθ/πθ不是1吗?让我们看看代码具体是怎么写的吧。
1
2
3
4
| # x - x.detach() allows for preserving gradients from x
per_token_loss = torch.exp(per_token_logps - per_token_logps.detach()) * advantages.unsqueeze(1)
per_token_loss = -(per_token_loss - self.beta * per_token_kl)
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
|
由于.detach()只是返回一个共享存储位置但没有梯度的tensor,所以per_token_logps - per_token_logps.detach()为0,torch.exp(per_token_logps - per_token_logps.detach())等于1,因此,此时的per_token_loss等于advantages。
只不过如果计算这一步的梯度的话,per_token_logps.detach()就要被看做常数C了,所以整体是有per_token_logps梯度的。
接下来的就跟论文里的Loss差不多了,所以要看第一步的loss,就要分别看KL和advantages(也就是reward)
(爆论在下一大章节的最后,请一定要看)
初始Loss为零的原因
第一步的KL为什么是0?
1
2
3
4
5
6
7
8
9
10
11
12
13
| with unwrap_model_for_generation(self.model, self.accelerator) as unwrapped_model:
prompt_completion_ids = unwrapped_model.generate(
prompt_ids, attention_mask=prompt_mask, generation_config=self.generation_config
)
ref_per_token_logps = self._get_per_token_logps(
self.ref_model, prompt_completion_ids, attention_mask, logits_to_keep
)
...
input_ids = torch.cat([prompt_ids, completion_ids], dim=1)
per_token_logps = self._get_per_token_logps(model, input_ids, attention_mask, logits_to_keep)
# Compute the KL divergence between the model and the reference model
ref_per_token_logps = inputs["ref_per_token_logps"]
per_token_kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
|
由于grpo在这边的原理是:
先由被训练模型(actor模型)推理生成prompt_completion_ids;
再把prompt_completion_ids给参考模型ref_model,生成ref_per_token_logps ;
把prompt_completion_ids给actor模型,拿到per_token_logps ;
最后KL = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
而在第一步的时候,actor模型此时权重与参考模型ref_model一致,所以per_token_logps = ref_per_token_logps ,代入公式中,所以KL=0 .
第一步的advantages为什么是0?
这边需要我们再看一下上文的GRPO Loss是怎么算的:
首先按照分组Group,对组内各样本(一个问题prompt生成num_generations个回答)进行标准化;
在最后计算loss时进行累加求均值的操作。
而具体的代码实现则是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # Sum the rewards from all reward functions
rewards = rewards_per_func.sum(dim=1)
# Compute grouped-wise rewards
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
# Normalize the rewards to compute the advantages
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4)
# Slice to keep only the local part of the data
process_slice = slice(
self.accelerator.process_index * len(prompts),
(self.accelerator.process_index + 1) * len(prompts),
)
advantages = advantages[process_slice]
...
# x - x.detach() allows for preserving gradients from x
advantages = inputs["advantages"]
per_token_loss = torch.exp(per_token_logps - per_token_logps.detach()) * advantages.unsqueeze(1)
per_token_loss = -(per_token_loss - self.beta * per_token_kl)
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
|
micro_batch_size必须是num_generations(一个问题生成多少个回答)的整数倍,为了简单起见,这里我们可以假设micro_batch_size=num_generations。
将每个子reward函数的值求和,得到一条样本的reward;
按照分组,算出num_generations个样本的mean_grouped_rewards 和std_grouped_rewards ;
将reward进行标准化,得到分组的advantages 。(按照进程切片,就是为了得到该进程(卡)上的分组advantages)
由于在上文已知,第一步的KL=0,所以此时的per_token_loss =advantages。再执行.sum(dim=1),即将组内的advantages求和。再执行.mean(),即得到了组间的advantages均值,即原始输入的问题个数的均值。
在这里我们可以注意到,第4步是对组内每个样本的reward进行标准化,第5步时对组内的标准化后的reward求和。那么对于标准化公式(ri - mean) / std 求和,就正好分子为0了。
换言之,其实GRPO Loss就等于βKL。只不过advantages可以在梯度计算中保留(见上文的.detach())。
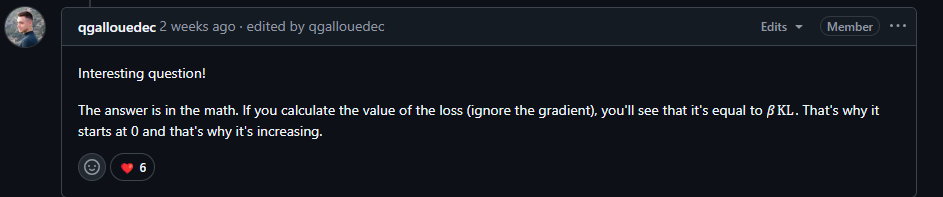
而上文说到,第一步的KL是0,所以第一步的loss一定是0.
有啥改进措施(加速方法)?
loss是0为啥还能训?
哈,用loss计算梯度,loss为0不代表梯度也为0。
而 梯度 * 学习率 才是模型能训练的原因。
改进措施
所以按照上文的思路,其实一开始100步几乎训不动,其实是因为学习率太小的缘故。
所以我们只需要关闭warmup,就可以从第一步开始训啦。
