AI_Agent让大模型使用工具

文章目录
背景
近一年,ai_agent变得异常火热,从某个方面来说,rag也是agent的一个tool而已,所以我们大胆的预判:未来是属于agent的。
ai_agent其实就是让大模型可以调用工具。但调用工具的前提是大模型的输出要满足一定的格式,这个格式我们叫做react。
现在的中文玩家很幸福,直接无脑使用qwen就可以了。但在几个月前,我刚刚开始玩ai_agent的时候,qwen2还没有发布,所以我选用的基础模型是chinese-llama3。但很快我就发现,llama3不支持react格式(要一直到llama3.1才支持)。
所以,我就准备自己微调出一个支持工具调用的chinese-llama3出来。(而且也方便大家去微调自己的格式输出)
创新点
大模型自生成微调语料
多轮对话的训练方式
提炼与问题相关的事实
以上创新点都会在下面详细过程中提到。
具体可见仓库:https://github.com/BZ-coding/ai_agent
我做了啥
要训练ai_agent,首先要做的就是弄到训练语料。但我翻了翻互联网,发现能找到的并且能用的react语料那是真的没有。所以我就准备自己生成训练语料。
而要生成ai_agent语料,首先我就要真的能跑一个ai_agent。
搭建自己的ai_agent流程
其实用langchain加载本地模型的方式,倒也能跑起来ai_agent,但由于中文的llama3并不能很好的遵从react格式,特别表现在大模型总是会把"Action: “输出成中文标点"Action:",然后langchain就会报错说找不到tool,这就很令人崩溃。而且在langchain的使用过程中也发现各种封装带来的不方便:比如我要想加上自己wrap的tool,直接load_tools竟然会报错,官方的解决方案竟是直接以list形式追加在load_tools的返回值后面。而且langchain也没有匹配llama3的模板,现象是llama3有概率一直说个不停。
所以,以上的一切不方便,加上ai_agent的流程其实并不难,最终让我决定,写一套自己的ai_agent流程:
定义tool的文本描述格式
此处参考了qwen的格式,我觉得该格式比langchain的格式描述更清晰,最主要的是,该格式几乎支持一切tool的输入格式,非常灵活。
定义agent的prompt
此处不管是qwen还是langchain,prompt的格式都几乎一致,当然我也跟他们一致。
解析大模型的输出
这点我对qwen的代码做了改进优化了解析各关键字(Action:、Action Input:、Observation:)的逻辑,能够更好的支持一些极端场景。
调用tool
此处得益于tool的描述文本,将输入参数的格式定义为json,使得支持任意参数的输入。同时我对各tool又封装了一层,用来解析json格式的参数。
将tool结果拼回大模型输入
这点就是很正常的再追加一轮多轮对话而已。但有点不方便的是,原来按我的设计,该轮对话的role应该是tool,但我用的统一后端是ollama,它加入了对于role的校验且只支持system、user、assistant这三个。关于这个问题,我跟ollama进行了交涉,但交涉的结果是ollama拒绝修改为可自定义。所以我只好把该轮对话的role改成assistant了。
再一个就是我对整体的输出做了流式输出的可选项,并且为了适配我后面人工校验语料的需求,做了各部分(大模型Thought反思和调用工具)的独立开关,可以从任意一步开始继续对话。

提炼与问题相关的事实
这个思路沿用的是我上一篇RAG的创新点,为的是解决web_search到的网页过长的问题。
具体是加入了对于过长的工具返回的字符串,提炼与问题相关的事实的能力。此举可以大幅减少冗余信息,提升cot思维链效果。

可以看到,与上图直接拼接网页源码的方式相比,提炼与问题相关的事实的方法,可以在不损失答案的情况下,减少冗余信息,明显的降低了内容文本长度。
大模型自生成微调语料全流程
上文有提到,我翻遍了互联网也没有找到能用的react语料,所以准备自己用大模型生成微调语料。
大模型自己生成ai_agent的问题
那么生成ai_agent微调语料的关键,或是说种子,就是一个合适的ai_agent问题。
所以我们首先设计prompt,让大语言模型自己生成这些问题种子:
| |
大模型检查生成的问题
但是生成语料这件事对人都是极为困难的,更别提大模型了,所以我们还需要对生成的问题作进一步的筛查,以选出真正需要用到tool才能解决的问题。
而常言道“检查总比生成要容易”,所以这一步我们仍然可以选用大模型来自动筛查:
| |
https://github.com/BZ-coding/ai_agent/blob/main/generate_finetune_sample/02_check_sample.py
在网页上人工校验LLM回答问题的输出
最后一步也是最重要的,就是要做一个网页来人工校验ai_agent的输出(即语料)。
因为如果全程都是大语言模型自己生成的话,等于说没有任何新知识的加入,在这种语料上继续训练反而会把大语言模型的参数空间拉向极端,从而越训越差。(这点其实早就是业界共识,但近期有篇论文专门构造了这个场景,然后现在的语料都遭到了LLM自身的污染,所以做出对LLM未来悲观的预判,因此这篇论文也遭到了业内的抨击)。
网页是用gradio写的,可以加载问题,并调用上文自建的ai_agent流程,逐步的显示每一轮对话,还可以任意的删改每一条输出,并接着修改后的内容继续进行ai_agent对话。最后,可以将对话的完整内容保存下来,形成一条ai_agent微调语料;或者直接把该条问题样本删除。

将llama3微调成支持工具调用的模型
由于我家里只有一张3090显卡,所以只能用LoRA去微调Llama3-8b模型,而且还必须把重计算打开。
并且就算是这样,我也训练不了长度大于9000的样本,所以只能把他们做成eval数据集。
训练过程&各实验: https://wandb.ai/bz-zhangshengdong/finetune_react_model/workspace
多轮对话的训练方法
在这里想跟大家讨论一下多轮对话的训练方法。
因为现在业界通行的多轮对话训练方式,一般就两种:
- 把多轮对话的语料拆成多条带历史对话信息的单条语料 这种训练方式会造成训练样本的膨胀,使得原本一次计算能完成的事变成要多次计算,降低了训练效率。
- 只训练最后一轮assistant的输出 这种训练方式把之前的对话都看作是历史对话,但之前每轮的assistant输出,就真的不需要校准学习吗?
所以我想的一种多轮对话训练的方式是:
利用label的标记,把每轮assistant的输出都标记成需要训练的正常label,其他地方全是忽略的标记(-100)。这样看起来,label就变成一段一段的了。
这种间隔标记label的多轮训练方式,好处在于可以在一次训练计算中,完成该多轮对话样本全部轮次的训练,提升了训练效率。并且多段loss取平均的方式,也与多条样本的loss取平均,在数学上是等价的。
https://github.com/BZ-coding/ai_agent/blob/main/finetune_react_model/utils/dataset.py
LoRA的学习率实验
根据qwen2的论文显示,其全参微调的学习率是7e-6。现在我的微调,其实只是格式上的调整,所以想的是学习率要小一点。但有别的研究显示,LoRA由于其低秩的特性,参数量少,所以学习率要大一点。
既然没有个统一的方法论,那我们就做个实验好了。
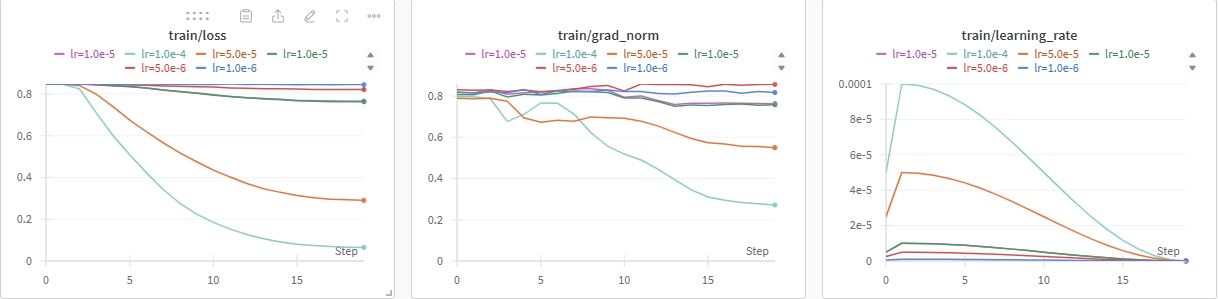
从图中可以发现,lr=1e-5时,其grad_norm下降得最为平稳,说明整体对原有的能力影响不大。而且loss的下降幅度并不巨大的同时,又有所下降,属于可以接受的范围。说明既没有明显破环原有能力,又对新格式有所学习。
所以最终选定学习率采用1e-5。
用ollama部署微调后的模型
虽然ollama官方文档里显示modelfile可以配置ADAPTER,但我尝试后,发现推理时ollama直接报错。
所以最终决定,还是把LoRA的参数merge到原始模型上,产生一个新模型,再用llama.cpp的脚本convert_hf_to_gguf.py转成gguf格式,最终载入到ollama里。